Background
It all started last year with a humble single drive DS111 which I bought for home, speculating that I could probably run Serviio on it to stream my movies to my DLNA enabled Bluray player. I managed to compile FFmpeg and its dependencies, install Java and get Serviio running and it has been golden ever since. Since then I’ve learned a lot more about Linux, packaged many other pieces of software and reverse-engineered my own Synology package repository, which at the last count over 5,000 NASes had checked into. The value of the Synology products lies in their great DSM software.
A few months later at work I decided to buy an RS411 to replace an appallingly slow FireWire Drobo (sub 10MB/sec!) that one of my colleagues was using to store video production rushes. Using the same four 2TB drives that had been inside the Drobo it has behaved impeccably – and it is currently in the process of mirroring 3TB to CrashPlan courtesy of my own app package. Having passed this test, I decided that Synology was a worthy candidate for a more serious purchase. However I noticed that there wasn’t much information about their SME products online so I’m sharing my research here.
The need for 2nd tier storage
I have used a 15K SAS EqualLogic iSCSI storage array for VMware workloads since 2009 but this is quite full. It can’t accommodate the data which I need to migrate from older arrays which are at end of life. This data (most of it flat files) is very much 2nd tier – I need lots of space, but I don’t really care too much about latency or throughput. It’s also predominantly static data. I do need at least some additional VMware storage, so I can use vMotion to decant and re-arrange VMs on other storage arrays. A larger Synology rack mount NAS therefore presents itself as a very good value way of addressing this need, while keeping the risk of failure acceptably low.
Which model?
The choice is actually pretty easy. A redundant power supply is fairly mandatory in business since this is the most likely thing to fail after a drive. The unit is under warranty for three years, but can you really survive for the day or two of downtime it would most likely take to get a replacement on site? Once this requirement is considered, there are actually very few models to choose from – just three in fact: the RS812RP+ (1U 4 bay), the RS2212RP+ (2U 10 bay) and the RS3412RPxs (2U 10 bay). The 4 bay model isn’t big enough for my needs so that narrows the field. The RS3412RPxs is quite a price hike over the RS2212RP+, but you do get 4 x 1GbE ports with the option of an add-in card with 2 x 10GbE ports. Considering that the EqualLogic PS4000XV unit I’m using for 1st tier storage manages fine with 2 x 1GbE on each controller I think this is a little overkill for my needs and besides, I don’t have any 10GbE switches (more on bandwidth later). Other physical enhancements are a faster CPU, ECC server RAM, and the ability to add two InfiniBand-connected RS1211 (2U 12 bay) expansion units rather than one.
Synology now offer VMware certified VAAI support from DSM 4.1 on the xs models (currently in beta). They actually support more VAAI primitives than EqualLogic, including freeing up space on a thin provisioned LUN when blocks are deleted. Dell EqualLogic brazenly advertised this as a feature in a vSphere 4.0 marketing PDF back in 2009 and I had to chase tech support for weeks to discover that it was “coming soon”. To date this functionality is still missing. The latest ETA is that it will ship with EqualLogic firmware 6.00 whenever that arrives. Though this is a software feature, Synology are using it to differentiate the more expensive products. More CPU is required during these VAAI operations, though blogger John Nash suggests that it isn’t much of an overhead.
If you need high performance during cloning and copying operations, or are considering using a Synology NAS as your 1st tier storage then perhaps you should consider the xs range.
Which drives?
The choices are bewildering at first. Many of the cheapest drives are the ‘green’ ones which typically spin at 5,400RPM. Their performance won’t be as good as 7,200RPM models, and they also tend to have more aggressive head parking and spindown timer settings in their firmwares. Western Digital ones are notorious for this to the extent that these drives have dramatically shorter lifespans if this is not disabled. To do this is tedious and requires a PC and a DOS boot disk. Making a bootable MS-DOS USB key can try the patience of even the calmest person!
UPDATE – it seems from the Synology Forum that DSM build 3.2-1922 and later will automatically disable the idle timer on these drives. You can check the status by running this one-liner while logged into SSH as root:
for d in `/usr/syno/bin/synodiskport -sata` ; do echo "*** /dev/$d ***"; /usr/syno/bin/syno_disk_ctl --wd-idle -g /dev/$d; done
You can force the disabling of the timer with that same tool:
/syno/bin/syno_disk_ctl --wd-idle -d /dev/sda
The next choice is between Enterprise class and Desktop class drives. This is quite subjective, because for years we have been taught that only SCSI/SAS drives were meant to be sufficiently reliable for continuous use. Typically the Enterprise class drives will have a 5 year manufacturer warranty and the Desktop ones will have 3 years. Often it takes a call to the manufacturer’s customer service helpline to determine the true warranty cover for a particular drive since retailers often seem to misreport this detail on their website. The Enterprise ones are significantly more expensive (£160 Vs £90 for a 2TB drive).
There is one additional feature on Enterprise class drives – TLER (Time Limited Error Recovery). There are a few articles about how this relates to RAID arrays and it proved quite a distraction while researching this NAS purchase. The concept is this: when a drive encounters a failed block during a write operation there is a delay while that drive remaps the physical block to the spare blocks on the drive. On a desktop PC your OS would hang for a moment until the drive responds that the write was successful. A typical hardware RAID controller is intolerant of a delay here and will potentially fail the entire drive if this happens, even though only a single block is faulty. TLER allows to drive to inform the controller that the write is delayed, but not failed. The side effect of not having TLER support would be frequent drive rebuilds from parity, which can be very slow when you’re dealing with 2TB disks – not to mention impairing performance. The good news though, is that the Synology products use a Linux software RAID implementation, so TLER support becomes irrelevant.
Given what’s at stake it’s highly advisable to select drives which are in the Synology HCL. The NAS may be able to overcome some particular drive firmware quirks in software (like idle timers on some models etc.), and their presence on the list does also mean that Synology have tested them thoroughly. I decided to purchase 11 drives so I would have one spare on site ready for insertion directly after a failure. RAID parity can take a long time to rebuild so you don’t want to be waiting for a replacement. Bear in mind that returning a drive under a manufacturer warranty could take a week or two.
Apparently one of the value-added things with enterprise grade SAN storage is that individual drives will be selected from different production batches to minimize the chances of simultaneous failures. This does remain a risk for NAS storage, and all the RAID levels in the world cannot help you in that scenario.
My Order
- Bare RS2212RP+ 10 bay rackmount NAS (around £1,700 – all prices are excluding VAT).
- 11 x Hitachi Desktar HDS723020BLA642 drives including 3 year manufacturer warranty (around £1,000).
- The unit has 1GB of DDR3 RAM soldered on the mainboard, with an empty SODIMM slot which I would advise populating with a 2GB Kingston RAM module, part number KVR1066D3S8S7/2G (a mere £10), just in case you want to install additional software packages later.
- Synology 2U sliding rack rail kit, part number 13-082URS010 (£80). The static 1U rail kit for the RS411 was pretty poorly designed but this one is an improvement. It is still a bit time consuming to set up compared to modern snap-to-fix rails from the likes of Dell and HP.
Setup – How to serve the data
A Synology NAS offers several ways to actually store the data:
- Using the NAS as a file server in its own right, using SMB, AFP, or NFS
- iSCSI at block level (dedicated partitions)
- iSCSI at file level (more flexible, but a small performance hit)
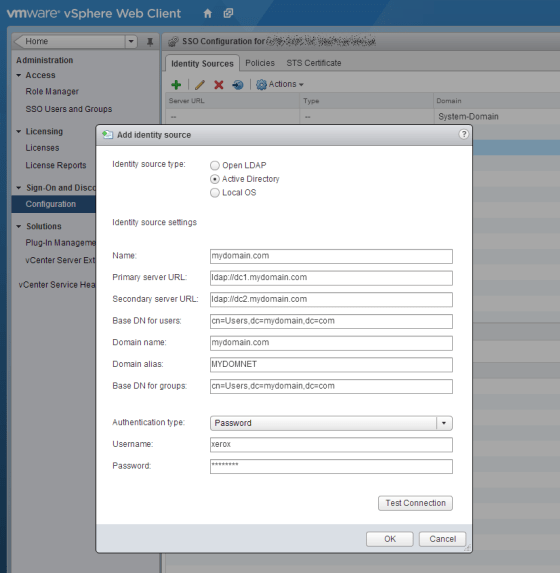
For my non-critical RS411, using it as an Active Directory integrated file server has proved to be very reliable. However, for this new NAS I needed LUNs for VMware. I could have perhaps defined a Disk Group and dedicated some storage to iSCSI, and some to a normal ext4 volume. I had experimented with iSCSI, but there are several problems:
- Online research does reveal that there have been some significant iSCSI reliability issues on Synology, though admittedly these issues could possibly date from when DSM first introduced iSCSI functionality.
- To use iSCSI multipathing on Synology the two NAS network interfaces must be on separate subnets. This is at odds with the same-subnet approach of Dell EqualLogic storage, which the rest of my VMware infrastructure uses. This would mean that hosts using iSCSI storage would need additional iSCSI initiators, significantly increasing complexity.
- It is customary to isolate iSCSI traffic onto a separate storage network infrastructure, but the Synology NAS does not possess a separate management NIC. So if it is placed on a storage LAN it will not be easily managed/monitored/updated, nor even be able to send email alerts when error conditions arise. This was a show-stopper for me. I think Synology ought to consider at least allowing management traffic to use a different VLAN even if it must use the same physical NICs. However, VLANing iSCSI traffic is something most storage vendors advise against.
All of which naturally lead us onto NFS which is very easy to configure and well supported by VMware. Multipathing isn’t possible for a single NFS share, so the best strategy is to bond the NAS network interfaces into a link aggregation group (‘Route Based on IP Hash’). This does mean however, that no hypervisor’s connection to the NFS storage IP can use more than 1Gbps of bandwidth. This gives a theoretical peak throughput of 1024/8 = 128MB/sec. Considering that each individual SATA hard disk in the array is capable of providing roughly this same sustained transfer rate, this figure is somewhat disappointing. The NAS can deliver much faster speeds than this but is restricted by its 1GbE interfaces. Some NFS storage appliances help to mitigate this limitation to a degree by allowing you to configure multiple storage IP addresses. You could then split your VMs between several NFS shares, each with a different destination IP which could be routed down a different physical link. In this way a single hypervisor could saturate both links. Not so for Synology NAS unfortunately.
If raw performance is important to you, perhaps you should reconsider the xs series’ 2 x 10GbE optional add-in card. Remember though that the stock xs config (4 x GbE) will still suffer from this NFS performance capping of a single NFS connection at 1GbE. It should be noted however that multiple hypervisors accessing this storage will each be able to achieve this transfer rate, up to the maximum performance of the RAID array (around 200MB/sec for an RS2212RP+ according to the official performance figures, rising to around 10 times that figure for the xs series – presumably with the 10GbE add-in card).
As per this blog post, VMware will preferentially route NFS traffic down the first kernel port that is on the same subnet as the target NFS share if one exists, if not it will connect using the management interface via the default gateway. So adding more kernel ports won’t help. My VMware hypervisor servers use 2 x GbE for management traffic, 2 x GbE for VM network traffic, and 2 x GbE for iSCSI. Though I had enough spare NICs, connecting another pair of interfaces solely for NFS was a little overkill, especially since I know that the IOPS requirement for this storage is low. I was also running out of ports on the network patch panel in that cabinet. I did test the performance using dedicated interfaces but unsurprisingly I found it no better. In theory it’s a bad idea to use management network pNICs for anything else since that could slow vMotion operations or in extreme scenarios even prevent remote management. However, vMotion traffic is also constrained by the same limitations of ‘Route Based on IP Hash’ link aggregation policy – i.e. no single connection can saturate more than one physical link (1GbE). In my environment I’m unlikely to be migrating multiple VMs by vMotion concurrently so I have decided to use the management connections for NFS traffic too.
Benchmarking and RAID level
I found the simplest way to benchmark the transfer rates was to perform vMotion operations while keeping the Resource Monitor app open in DSM, and then referring to Cacti graphs of my switch ports to sanity check the results. The network switch is a Cisco 3750 two unit stack, with the MTU temporarily configured to a max value of 9000 bytes.
- Single NFS share transfer rates reading and writing were both around 120MB/sec at the stock MTU setting of 1500 (around 30% CPU load). That’s almost full GbE line speed.
- The same transfers occurred using only 15% CPU load with jumbo frames enabled, though the actual transfer rates worsened to around 60-70MB/sec. Consequently I think jumbo frames are pointless here.
- The CPU use did not significantly increase between RAID5 and RAID6.
I decided therefore to keep an MTU of 1500 and to use RAID6 since this buys a lot of additional resilience. The usable capacity of this VMware ready NAS is now 14TB. It has redundant power fed from two different UPS units on different power circuits, and it has aggregated network uplinks into separate switch stack members. All in all that’s pretty darn good for £2,800 + VAT.